Recent News
2024/10
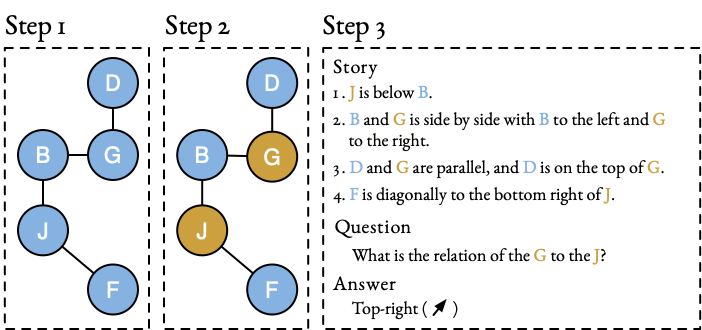
New preprint on likelihood over-optimisation in direct alignment algorithms is now available on arXiv.
2024/09
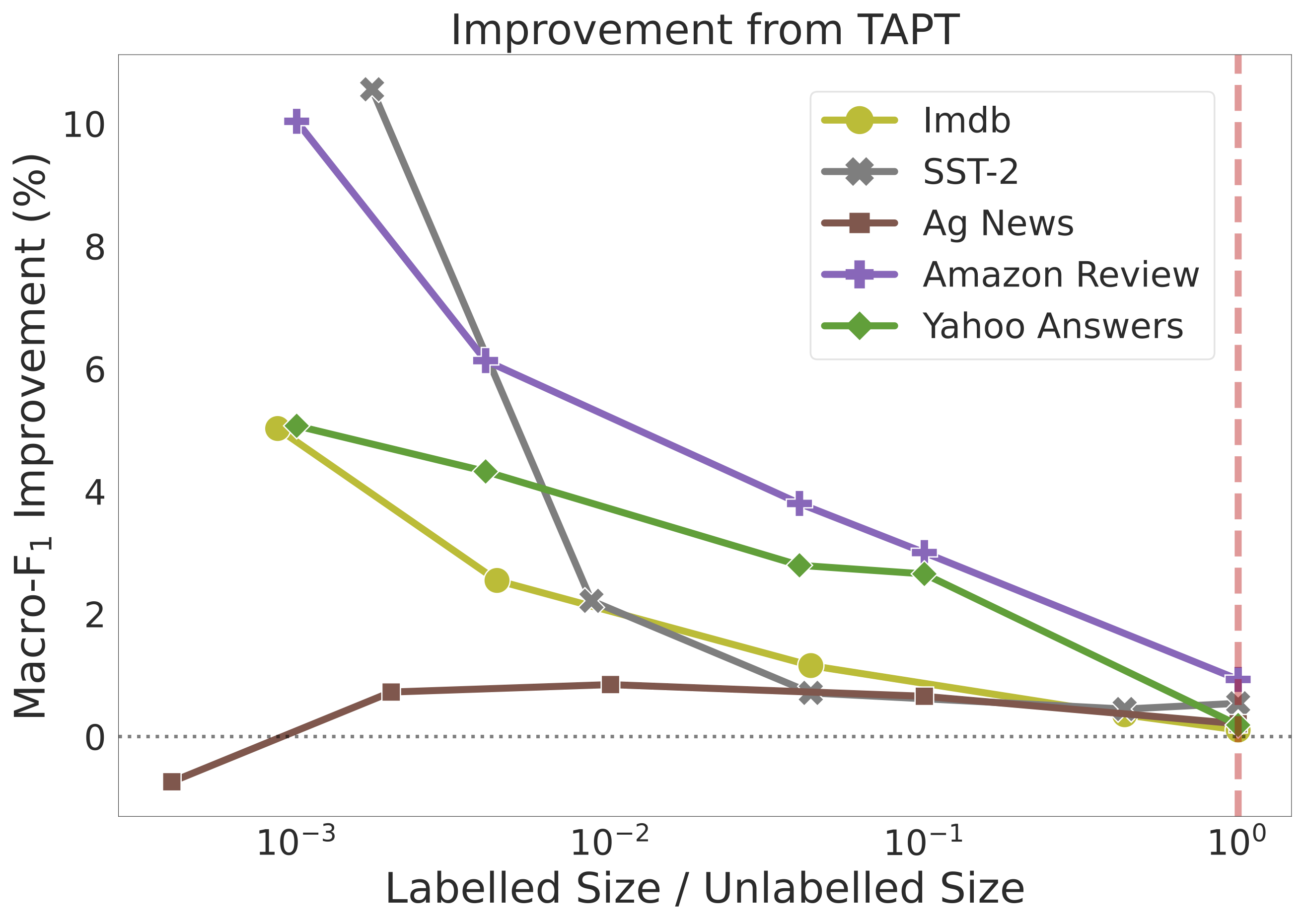
Paper on "Instruction Tuning With Loss Over Instructions" accepted to NeurIPS 2024!
2024/01
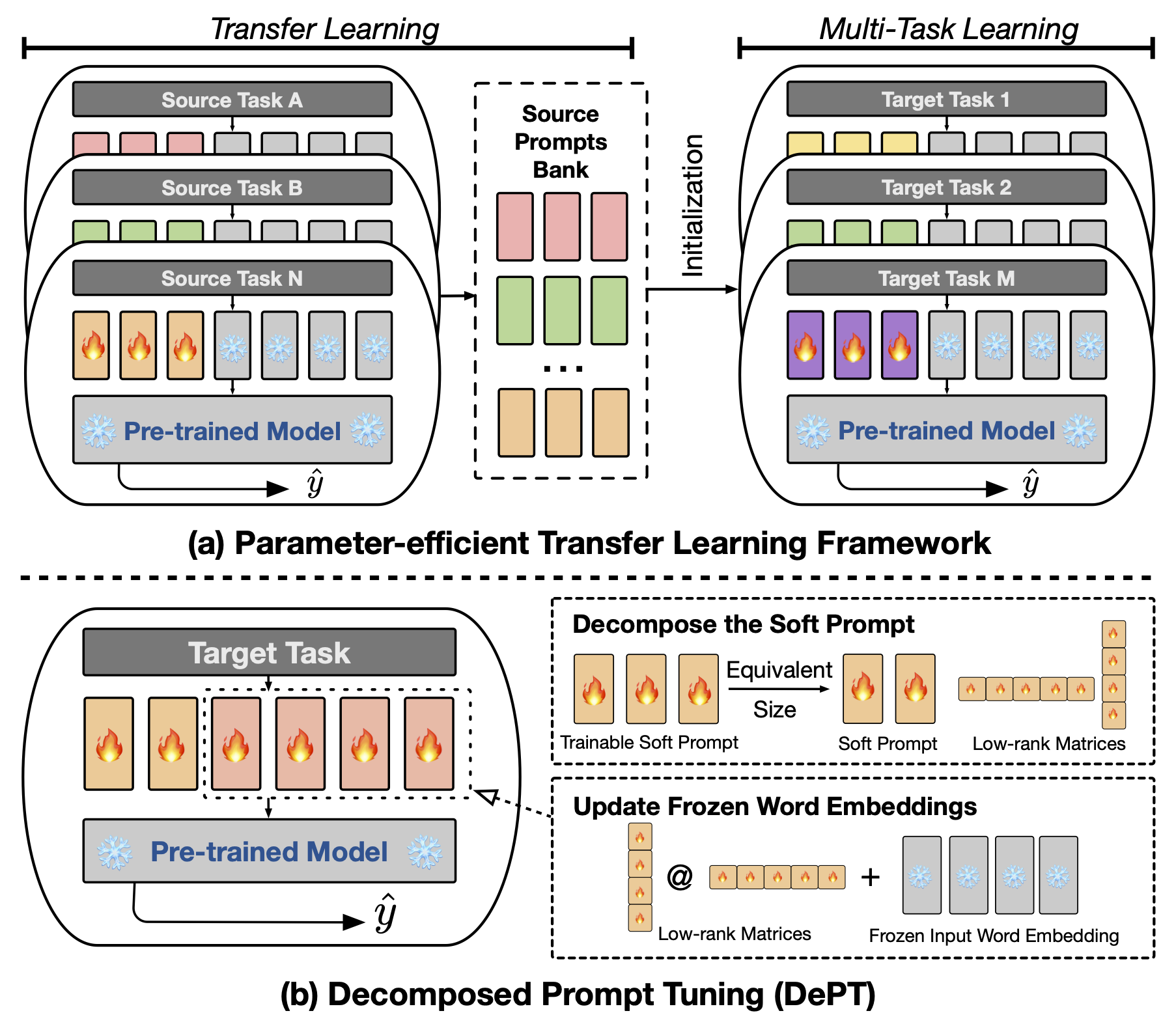
Paper on "DePT: Decomposed Prompt Tuning" accepted to ICLR 2024!
2023/09
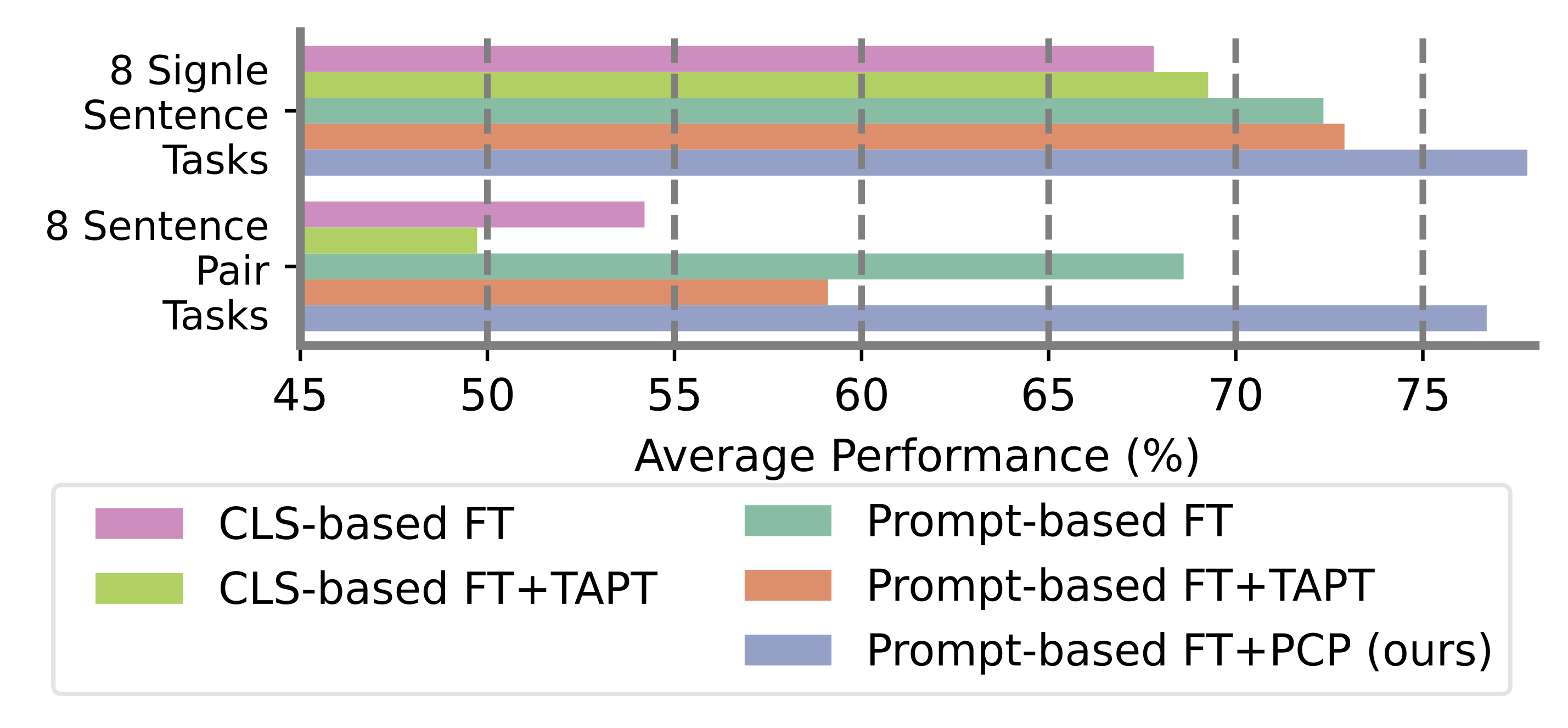
Paper accepted to NeurIPS 2023 on powerful prompt-based fine-tuning!
Academic Services
Program Committee: NeurIPS (2023, 2024), ICML (2024), ICLR (2025), AAAI (2023, 2024), COLM (2024), ACL ARR (Feb. 2023 - Jan. 2024), ACL (2023), EMNLP (2022, 2023), EACL (2023), COLING (2023, 2024), ECML/PKDD (2022), KDD (2023), SIGIR (2022, 2023, 2024), ECIR (2024), SDM (2024)